
Using the power curve to understand your cycling performance. Part 1: getting the data.
This is a series of blog posts in which I outline what I hope is a helpful way to use cycling power meter data to track your progress over time. In this first post, I go through the steps to put your cycling activity data into an analyzable format. I’ll assume you have a Strava account. If you don’t, you’ll have to replace the first step below with some other way of obtaining the .fit files that contain the required information about your activities.
Step 1: Bulk export your data
To get started, we’ll need to obtain our raw activity data. How exactly you can do this depends on the specific devices and apps that you’re using. For example, if you use Garmin Connect or Strava, you can download the .fit files by loggin in to either service from your web browser. The process that I used was that of bulk exporting my activities from Strava. In short, this process generates a link that you can use to download all your Strava account data, including the compressed .fit files containing your activity records. The .fit files are located in a folder called “activites”.
Step 2: Generate a list of file names
Once we have our activity files in a folder, we can use the fitparse library to extract their contents. If you haven’t installed fitparse before, you’ll need to follow the steps outlined in the above link. Let’s start by loading some standard libraries and importing the “FitFile” class from fitparse:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import os
import gzip
from fitparse import FitFile
We can now use the following function to obtain a list of the names of your activity files. Please replace the “~/path/to/folder” string with the actual path to your activites folder. If your .fit files are not compressed, you can omit the ‘.gz’ part from the file_ends_with argument.
dir_as_str = '~/path/to/folder'
def get_file_names(dir_as_str, file_ends_with='.fit.gz'):
'''
Get a list of file names ending with file_ends_with
from a directory.
Args
----
dir_as_str : str
Path to the directory containing your .fit files.
file_ends_with : str
The file name ending that is used to identify the right
files in the folder, eg '.fit'
Returns
-------
file_name_list : list
A list of file names ending with file_ends_with.
'''
file_name_list = []
activity_directory = os.fsencode(dir_as_str)
for file in os.listdir(activity_directory):
file_dec = os.fsdecode(file)
if file_dec.endswith(file_ends_with):
file_name_list.append(file)
else:
pass
return file_name_list
file_name_list = get_file_names(dir_as_str)
We now have a list of the names of our activity files.
Step 3: Extract the contents of the .fit files
As the final step, we need to loop through our compressed .fit files and extract the relevant information from those files in a more easily manageable form. To do so, we can use the function below. The execution may take some time if you have a lot of activity files.
def get_activity_history(dir_as_str, file_name_list):
'''
Extract a list of activity records from .fit files in the
folder located in dir_as_str.
Args
----
dir_as_str : str
Path to the directory containing your .fit files.
file_name_list : list
A list of the names of the .fit files.
Returns
-------
activity_history : list
A list of activity data extracted from your .fit files.
'''
activity_directory = os.fsencode(dir_as_str)
activity_history = []
for run_id, zipped_file in enumerate(file_name_list):
zipped_file_path = os.path.join(activity_directory, zipped_file)
fit_file = gzip.open(zipped_file_path)
fit_file_read = fit_file.read()
fit_file.close()
fit_file_pars = FitFile(fit_file_read)
activity = []
for record in fit_file_pars.get_messages('record'):
record_dict = {}
for record_content in record:
record_dict[record_content.name] = record_content.value
activity.append(record_dict)
activity_history.extend(activity)
num_files = len(file_name_list)
if run_id % round(num_files * 0.1, 0) == 0:
pct_compl = round(run_id / num_files, 2) * 100
print(f'''{pct_compl}% completed''')
return activity_history
activity_history = get_activity_history(dir_as_str, file_name_list)
Since we’re going to manipulate the activity data in the following installments of this blog post series, we’ll put the data into a pandas DataFrame and save it as a .csv file for further reference. We’ll also index the DataFrame using the timestamp for each record, contained in the “timestamp” column of the DataFrame.
activity_df = pd.DataFrame(activity_history)
activity_df.set_index('timestamp', drop=True, inplace=True)
activity_df.to_csv('activity_history_7_july_2020.csv')
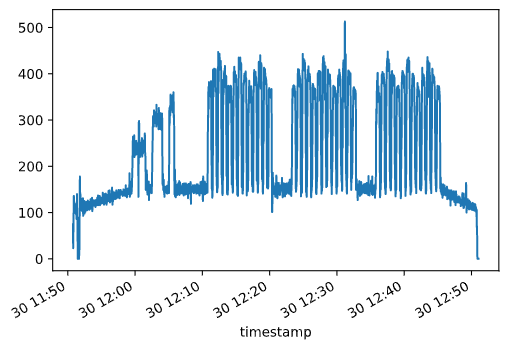
We can also perform a sanity check to see that the data makes sense. For example, last week I did some intervals that should show up in the power data if the above process has been successful. The power data is contained in the “power” column of the DataFrame.
activity_df.loc['2020-06-30', 'power'].plot()
As it happens, the above returns what looks like exactly the right data:
The DataFrame can now be used to perform all kinds of analyses. In the next installment, I’ll describe how we can use historical power data to track how our training and performance have progressed over time.
Acknowledgements
The following resources were particularly helpful: